
![]()
![]()
![]()
![]()
![]()
教師あり学習とは、何らかの方法で観測されたデータの特徴と、そのデータに関連する何らかのラベルとの関係をモデル化することを言います。この学習済みのモデルは、新しい未知のデータにラベルを付与するために使用できます。最もよく知られているパッケージとしてscikit-learnというものがあり、これを利用した教師あり学習の例をみてみましょう。
scikit-learnのデータを把握する最も良い方法は、データを表として捉えることです。基本的な表は2次元の格子状データです。ここではアイリスデータセットを用います。データの各行は観測された1つの花を表し、行の数はデータセット内の花データの総数です。
データをプロットすると以下のようなグラフができます。
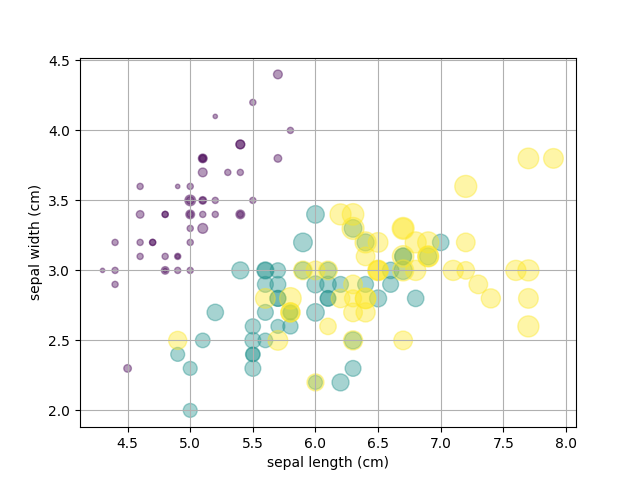
3種類のアイリスについてがく片の長さと幅の関係をプロットしたものです。
一般的にはデータの行をサンプルと呼び、行数をnサンプルのように呼びます。同様にデータの各列は各サンプルの特徴を表す量的情報を持ちます。一般的には行列の列を特徴量と呼び、列数をn特徴量のように呼びます。
nサンプル,n特徴量を持つ行列は特徴量行列と呼ばれます。これに対して特徴量から予測したい量は目的配列と呼ばれます。例えばアイリスデータを使用して、がく片や花びらの測定値からアイリスの種類を予測するモデルを構築する場合、種類の列は目的配列とみなされます。
ここでアイリスデータの一部を学習したモデルが残りのデータのラベルをどの程度正しく予測できるかを見ていきます。ここではガウシアンナイーブベイズ(Gaussian naive Bayes)と呼ばれる非常に単純なモデルを使用します。これは各クラスが軸毎にガウス分布を持つと仮定して処理を行います。
学習時のデータとは異なるデータでモデルを評価したいため、データを学習セットとテストセットに分割します。
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
iris=sns.load_dataset('iris')
X_iris=iris.drop('species',axis=1)
y_iris=iris['species']
Xtrain,Xtest,ytrain,ytest=train_test_split(X_iris,y_iris,random_state=1) #データを学習セットとテストセットで分ける。
model=GaussianNB()
model.fit(Xtrain,ytrain)
y_model=model.predict(Xtest) #新しいデータに対する予測
print(accuracy_score(ytest,y_model))
これを実行すると0.9736842105263158となり、非常に単純なアルゴリズムでも、97%の正確さで効果があることがわかります。

