
![]()
![]()
![]()
![]()
![]()
教師なし学習ではデータに関連するラベルを使用せずにデータセットの特徴をモデル化します。このモデルにはクラスタリングや次元削減などが含まれます。クラスタリングアルゴリズムはデータを区別するグループを識別し、次元削減アルゴリズムはデータのより簡潔な表現を見つけます。
機械学習ではscikit-learnと呼ばれるモジュールを利用するのが一般的ですが、その中で最も理解しやすいアルゴリズムであるk平均法クラスタリングの例を見てみましょう。
k平均法アルゴリズムは、ラベル付されていない多次元データセットから、与えられた数のクラスタを探します。これは最適なクラスタリングはどのように見えるかという、次のような単純な概念に基づいています。
・クラスタの中心は、クラスタに属する全てのポイントの算術平均である。
・各ポイントは、他のクラスタ中心よりも自分の属するクラスタの中心に近い。
ここでは画像の減色を例に見ていきます。例えば数百万色を使用した画像があるとすると、ほとんどの画像では、多くの色は使用されず、画像内の多数のピクセルは同じ色または似たような色を持ちます。
そこでk平均法を使用してピクセル空間全体のクラスタリングを行い、16色にまで減らす作業を行います。非常に大きなデータセットを処理するため、標準のk平均法アルゴリズムよりもはるかに高速に結果を計算できる、データのサブセットを操作するミニバッチk平均法を使用します。もとのピクセルの色を変更し、各ピクセルに最も近いクラスタ中心の色を割り当てます。コードは以下の通りです。
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from sklearn.cluster import MiniBatchKMeans
leaf=np.array(Image.open("P3300097_2.JPG")) #写真のデータをnumpy配列として読み込む
print(leaf.shape)
data=leaf/255.0
data=data.reshape(-1,3)
print(data.shape)
def plot_pixels(data,title,colors=None,N=10000):
if colors is None:
colors=data
rng=np.random.default_rng(0)
i=rng.permutation(data.shape[0])[:N]
colors=colors[i]
R,G,B=data[i].T
fig,ax=plt.subplots(1,2,figsize=(16,6))
ax[0].scatter(R,G,color=colors,marker='.')
ax[0].set(xlabel='Red',ylabel='Green',xlim=(0,1),ylim=(0,1))
ax[1].scatter(R,B,color=colors,marker='.')
ax[1].set(xlabel='Red',ylabel='Blue',xlim=(0,1),ylim=(0,1))
fig.suptitle(title,size=20);
kmeans=MiniBatchKMeans(16)
kmeans.fit(data)
new_colors=kmeans.cluster_centers_[kmeans.predict(data)]
leaf_recolored=new_colors.reshape(leaf.shape)
fig,ax=plt.subplots(1,2,figsize=(16,6),subplot_kw=dict(xticks=[],yticks=[]))
fig.subplots_adjust(wspace=0.05)
ax[0].imshow(leaf)
ax[0].set_title('Original Image',size=16)
ax[1].imshow(leaf_recolored)
ax[1].set_title('16-color Image',size=16);
plt.show()
この新しい色を画像としてプロットしたものは以下のようになります。
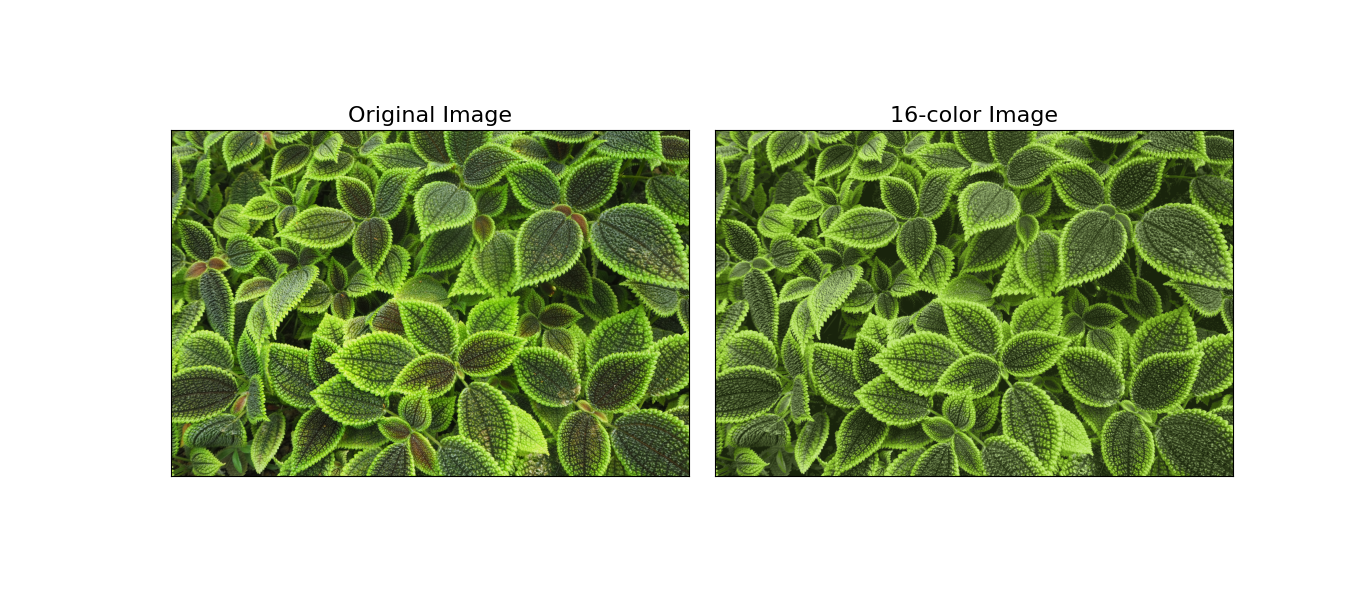
この例はデータの中身とは無関係に行えるk平均法のような教師なし学習手法の持つ力を示しています。
他にも教師なし学習の例として、以下の2つの例を紹介します。

